Layout Parser
Introducing an open-source deep-learning powered library, Layout Parser, that provides a variety of tools for automatically processing document image data at scale. Webpage; Arxiv; Github
Social science research often relies on scans of documents such as statistical tables, newspapers, firm level reports, etc.
Unfortunately, OCR is not designed to detect document layouts, except in cases where layouts are extremely simple. The below figures show typical OCR bounding boxes. Much of the text is not detected, and some is detected twice or scrambled. The OCR cannot distinguish different text types, ie headlines v captions v articles. This means OCR alone cannot power the end-to-end conversion of document image scans into structured databases.

Contrast the off-the-shelf OCR with the layout detection results we achieve through Layout Parser’s deep learning powered full document image analysis pipelines. The colors of the bounding boxes denote different types of text regions that are automatically classified by our DIA pipelines. Automatic classification of different meaningful text regions is required to automate the conversion of raw document scans into structured databases.
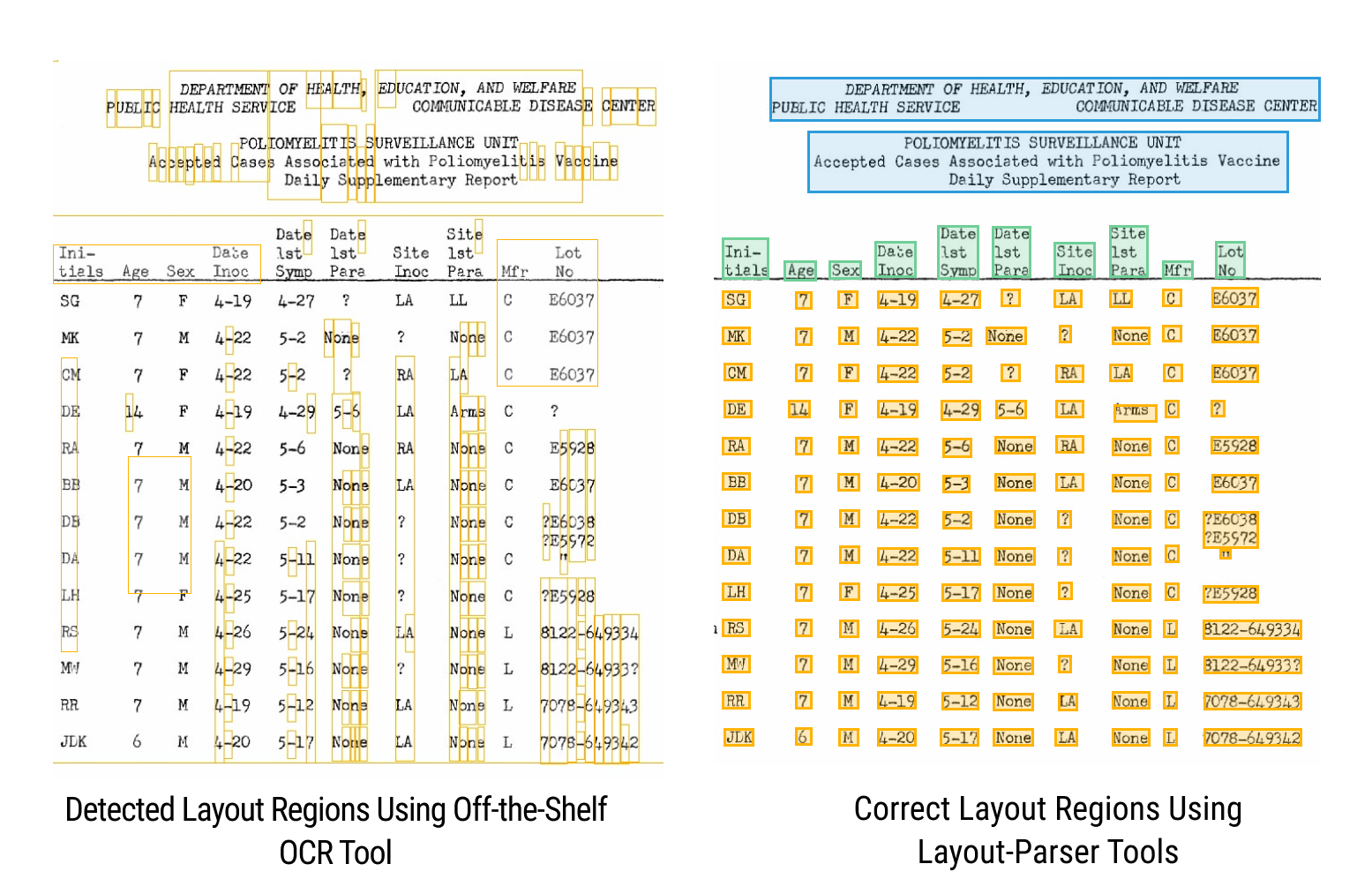
We have used Layout Parser to process tens of millions of such documents
Layout Parser is not just for English. Here’s another example, a complex historical table from Japan.
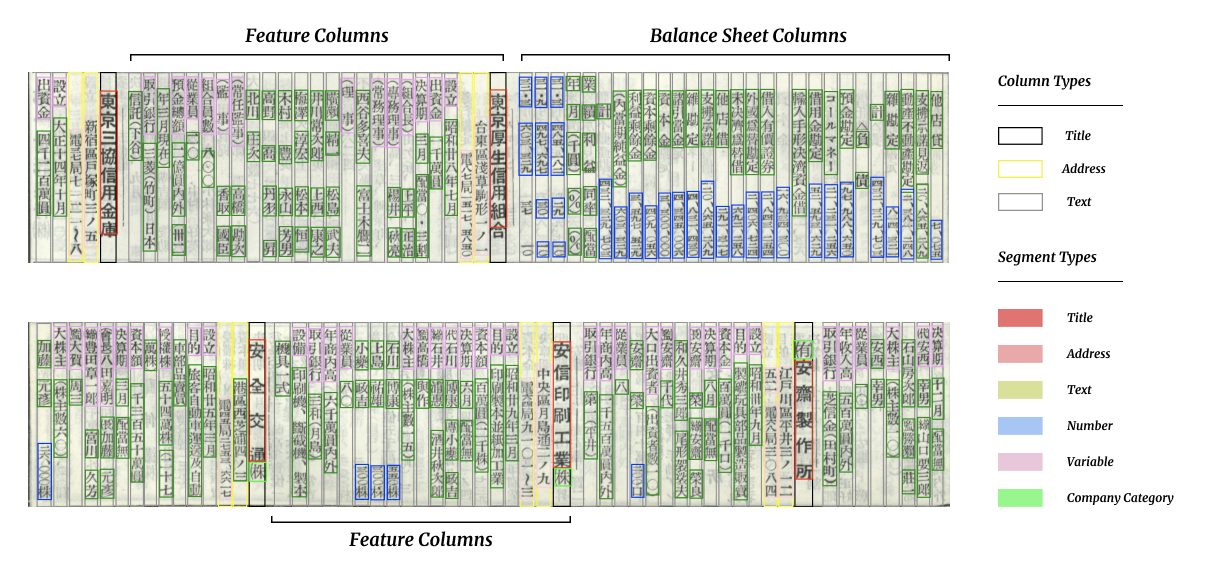
With Layout Parser, you can train your own customized DL-based layout models. The Layout Parser pre-trained models can provide a useful starting point via transfer learning.
Layout Parser builds wrappers to call OCR engines.
Layout Parser also provides a flexible output structure to facilitate diverse downstream analyses.
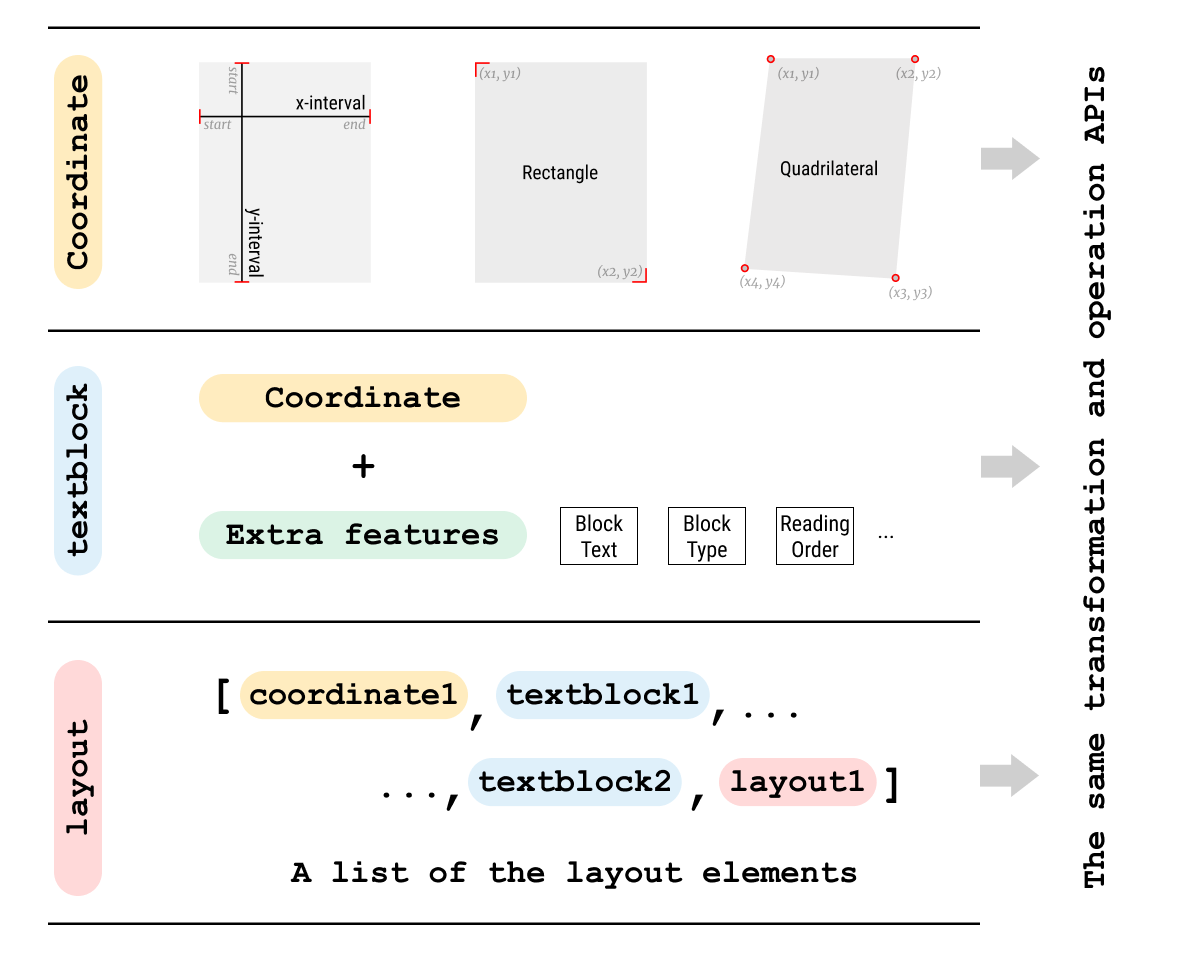
Layout Parser is implemented with simple APIs and can perform off-the-shelf layout analysis with four lines of Python code.
No background in deep learning? See the knowledgebase section of this site for lecture videos from my course on deep learning for data curation.