HomoglyphsCJK
Introducing HomoglyphsCJK, an easy-to-use python package for deep learning-assisted string matching. HomoglyphsCJK currently supports Simplified and Traditional Chinese, Korean, and Japanese.
The basic idea is to use vision transformers – a deep neural network – to quantify character visual similarity. The model is contrastively trained to learn a metric space where different augmentations of the same character (e.g., from different fonts) are represented nearby. This figure illustrates examples of the same character rendered with different fonts. Augmentations of these comprise positive examples in the homoglyphs training data.

The Homoglyphs model can be used to measure the similarity between different characters, which we show can significantly improve string matching accuracy for OCR’ed databases. This figure illustrates the five nearest neighbors in the HOMOGLYPH embedding space for representative characters.
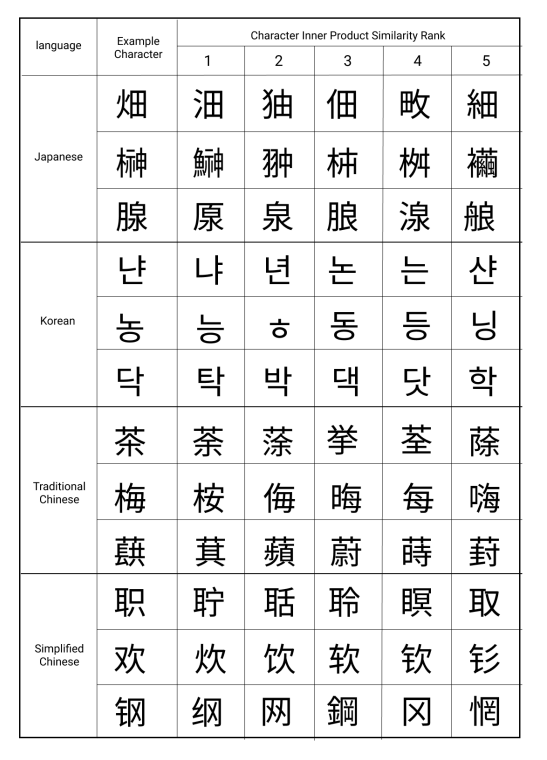
When homoglyphic matching fails, it is often because OCR has destroyed too much information for string matching to be a realistic solution.

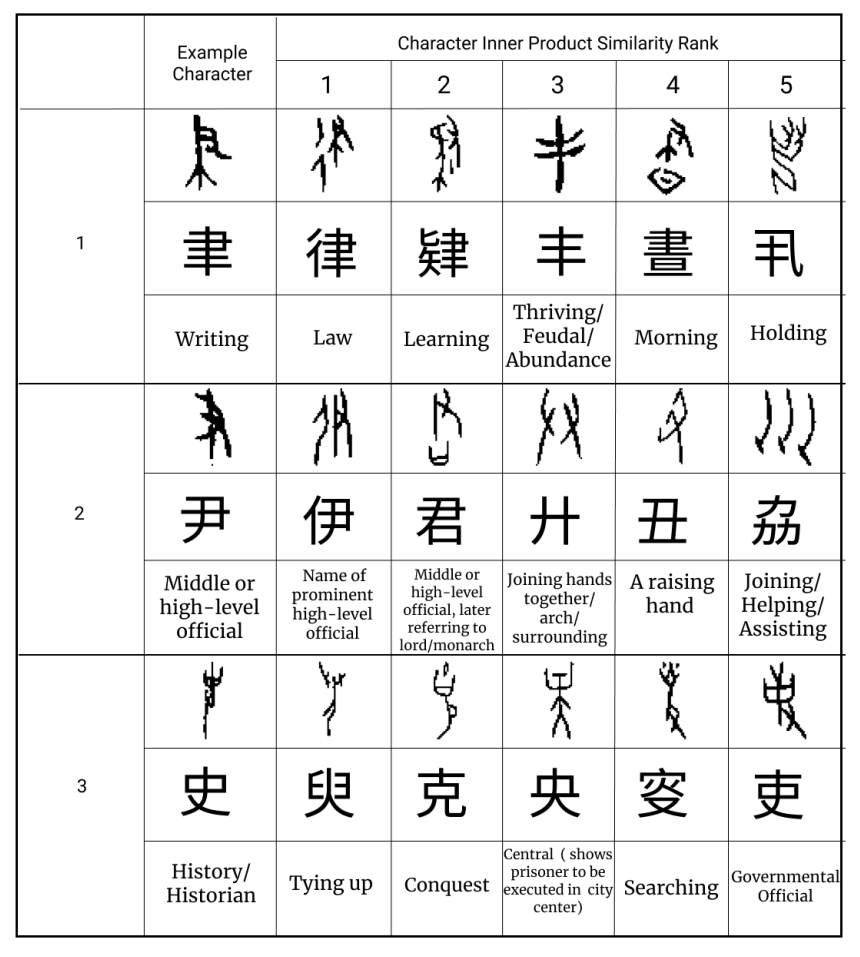
Our method for quantifying character similarity is purely self-supervised (it doesn’t require human-created labels), so it can be cheaply extended to any character set. Homoglyphs for ancient Chinese characters from over 3,000 years ago capture related abstract concepts noted in the archaeological literature. This figure shows homoglyph sets constructed for ancient Chinese, with the descendent modern Chinese character and a description of the ancient character’s meaning (which can differ from the descendent’s meaning).