HEADLINES
HEADLINES is a massive-scale dataset containing over 34 million front page headlines, drawn from historical U.S. off-copyright newspapers. The headlines describe over 6 million unique news wire articles. Around half of content in historical local newspapers came from newswires (e.g., the AP) but local papers wrote their own headlines. Headlines corresponding to the same wire article capture semantic similarity - texts that say similar things in different ways - and HEADLINES contains nearly 400 million semantic similarity pairs.

Many interesting tasks in natural language processing require a language model trained on semantic similarity data. Existing training data are largely from web texts; we are excited to release a massive-scale historical texts dataset. Headlines are also fascinating from a social science perspective
HEADLINES has broad geographic coverage:
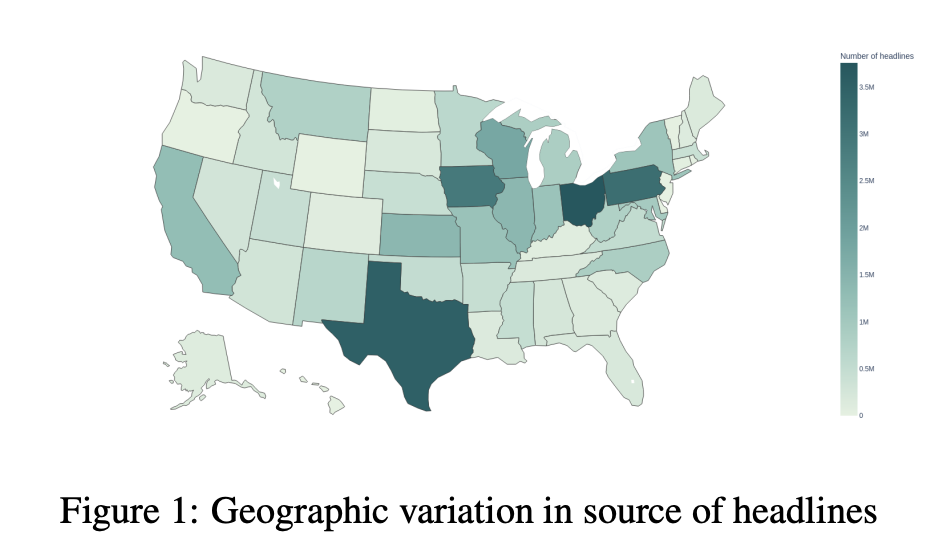
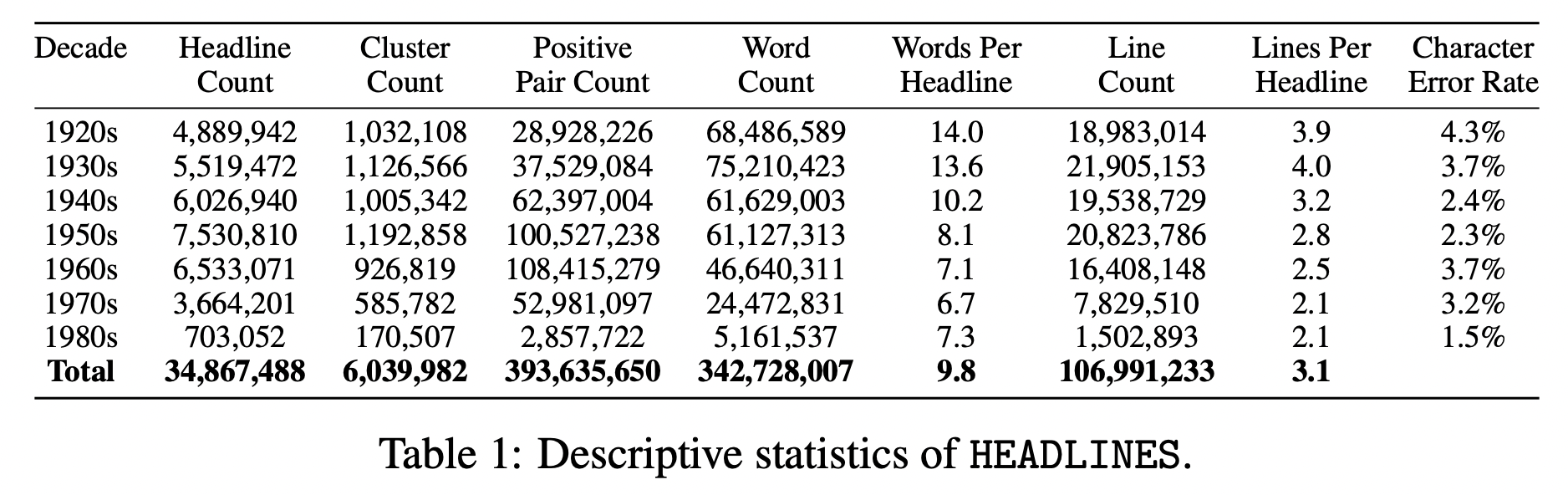
And the scale of the dataset is massive:
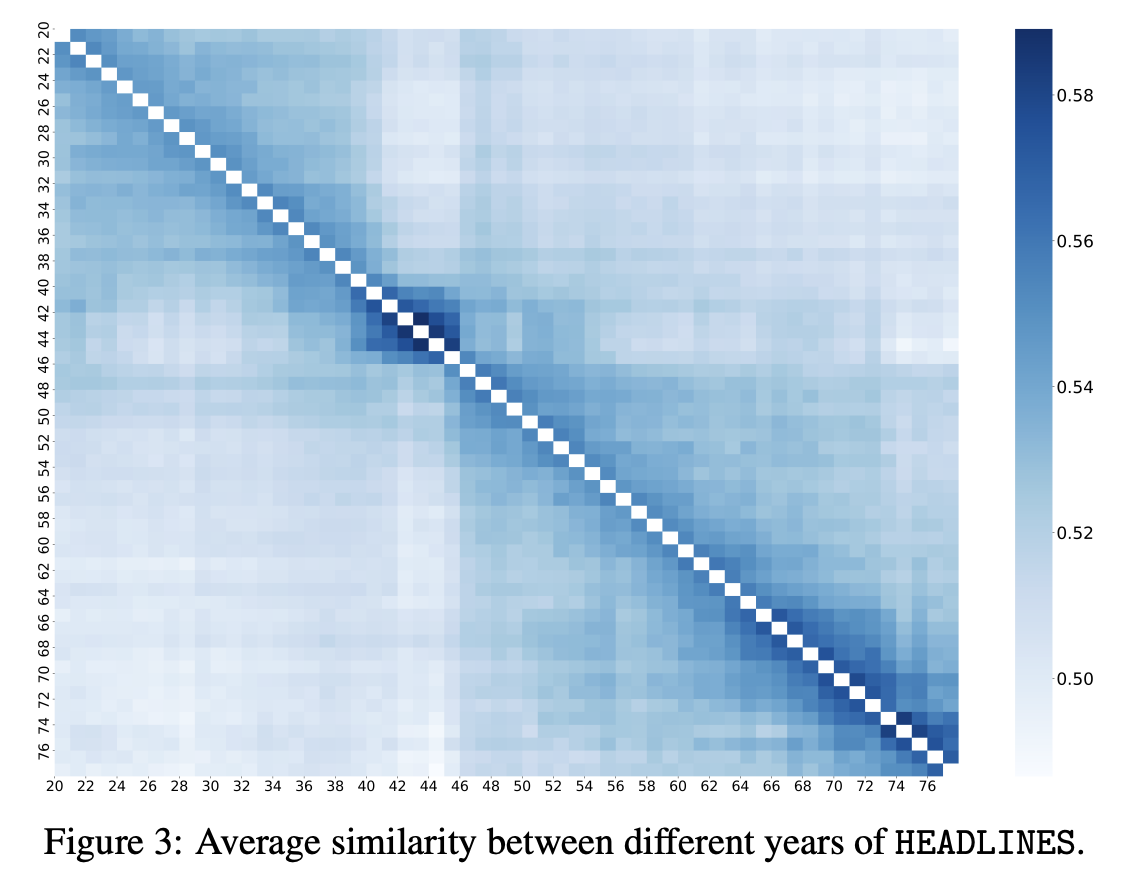
In the paper, we measure the semantic similarity of headlines across years, using a large language model. Content becomes more dissimilar as time elapses. The dark blue box in the center of the figure represents the World War II years, where content tended to be more similar and homogenous across time.
The paper also compares HEADLINES to other datasets - mostly taken from modern web texts. We conduct an exercise where we take a headline and compute the most semantically similar text in various modern web text datasets. Here are some examples (higher numbers mean more similar texts, as measured by a language model). Results underscore that in many cases, HEADLINES provides quite distinct data from what is available in various modern web text datasets:
