American Stories
Introducing American Stories, a new billion-scale dataset of structured texts/layouts from public domain newspapers (1780-1960) that we’ve built using our deep learning packages.
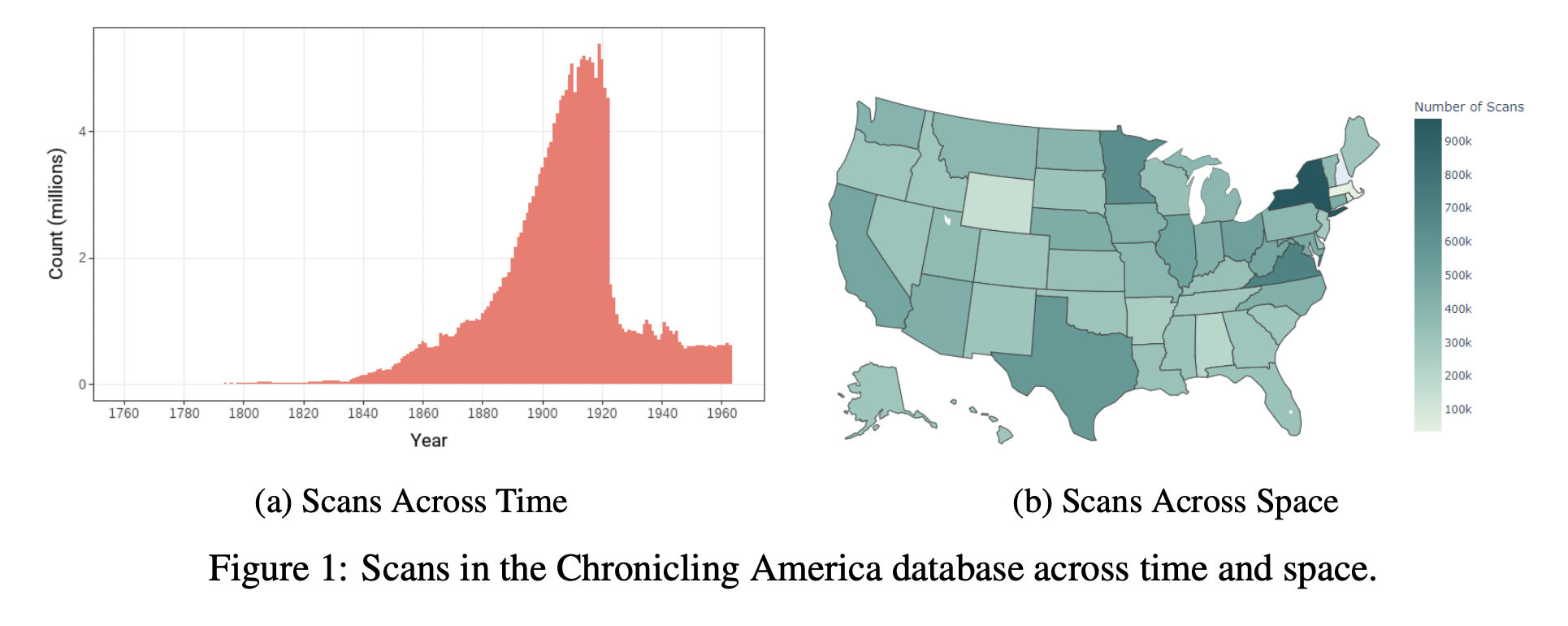
We detect 1.14 billion individual content regions in around 20M newspaper scans from Library of Congress’s Chronicling America collection. Headlines, articles, bylines, and captions are custom-OCRed. The dataset contains 438 million structured article texts.

It covers all 50 states, with content concentrated pre-1920.
The pipeline is highly efficient to deploy and has been open-sourced. We’ve also created open-source packages – LayoutParser and EfficientOCR – to help researchers develop similar pipelines for their own document collections.
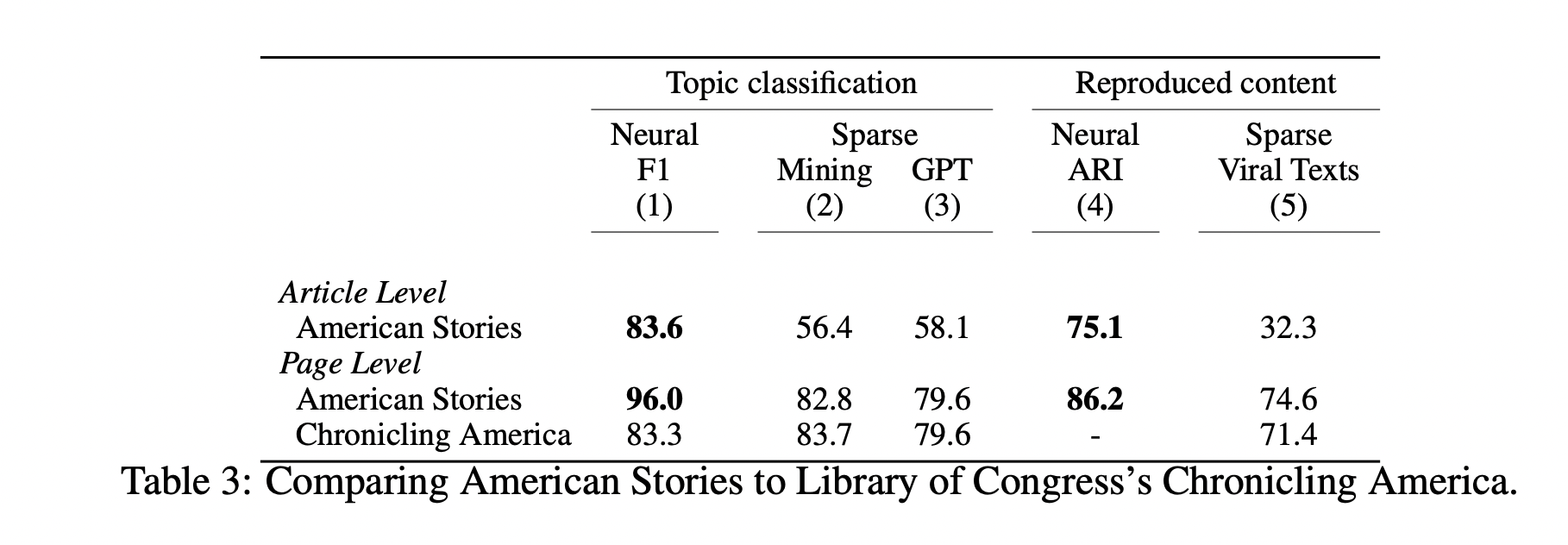
The existing Chronicling America OCR from Library of Congress doesn’t recognize layouts, scrambling articles, headlines, ads, etc. American Stories significantly improves accuracy on text classification (allowing it at the article level) and on detecting reproduced content.
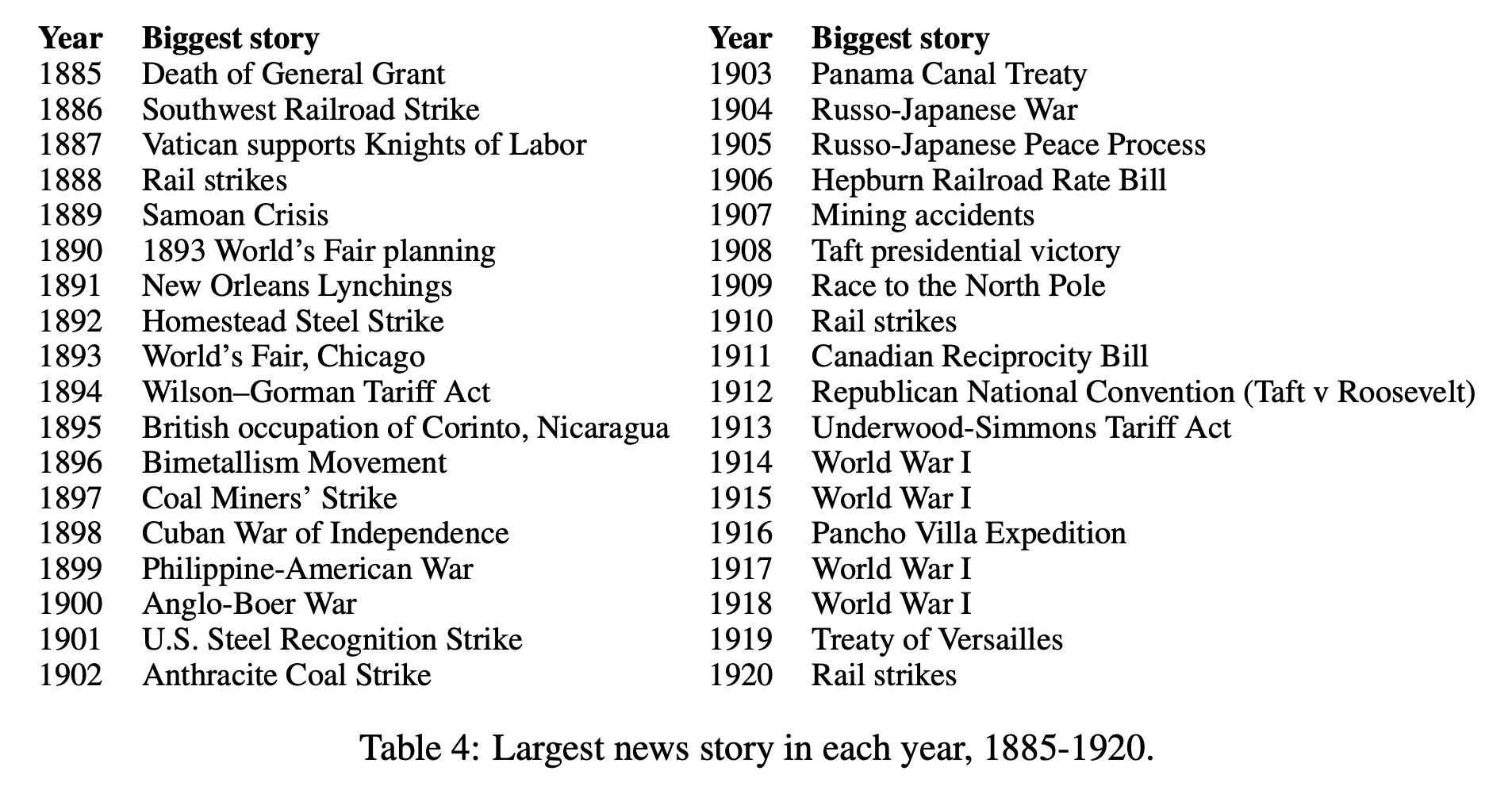
Structured article texts also support analyses that are impossible with existing page level texts. We detect the biggest stories of the year, using a custom trained large language model to embed texts and then applying clustering to group articles into coherent stories.
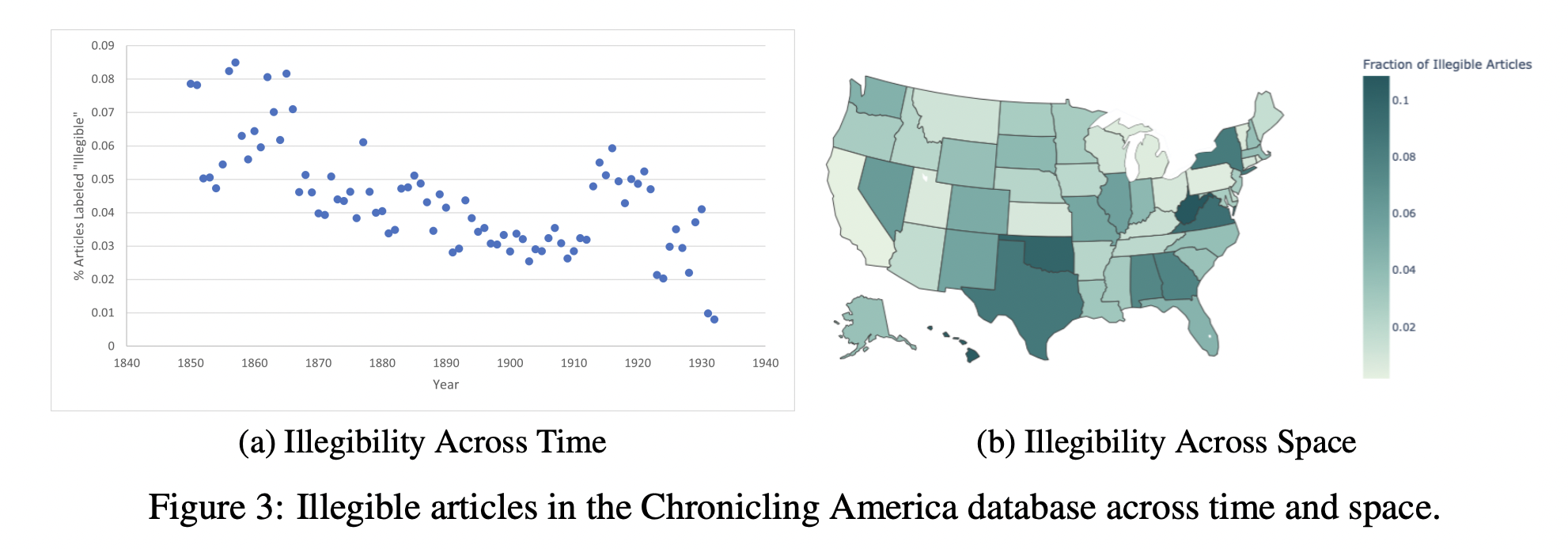
Another distinguishing feature of American Stories: after detecting text regions (articles, headlines, captions, bylines), we classify whether they are legible.

This is important because there are lots of illegible scans, with illegibility varying across space and time. Illegibility could bias analyses if researchers include illegible content in the denominator when measuring the presence of different terms or textual features.
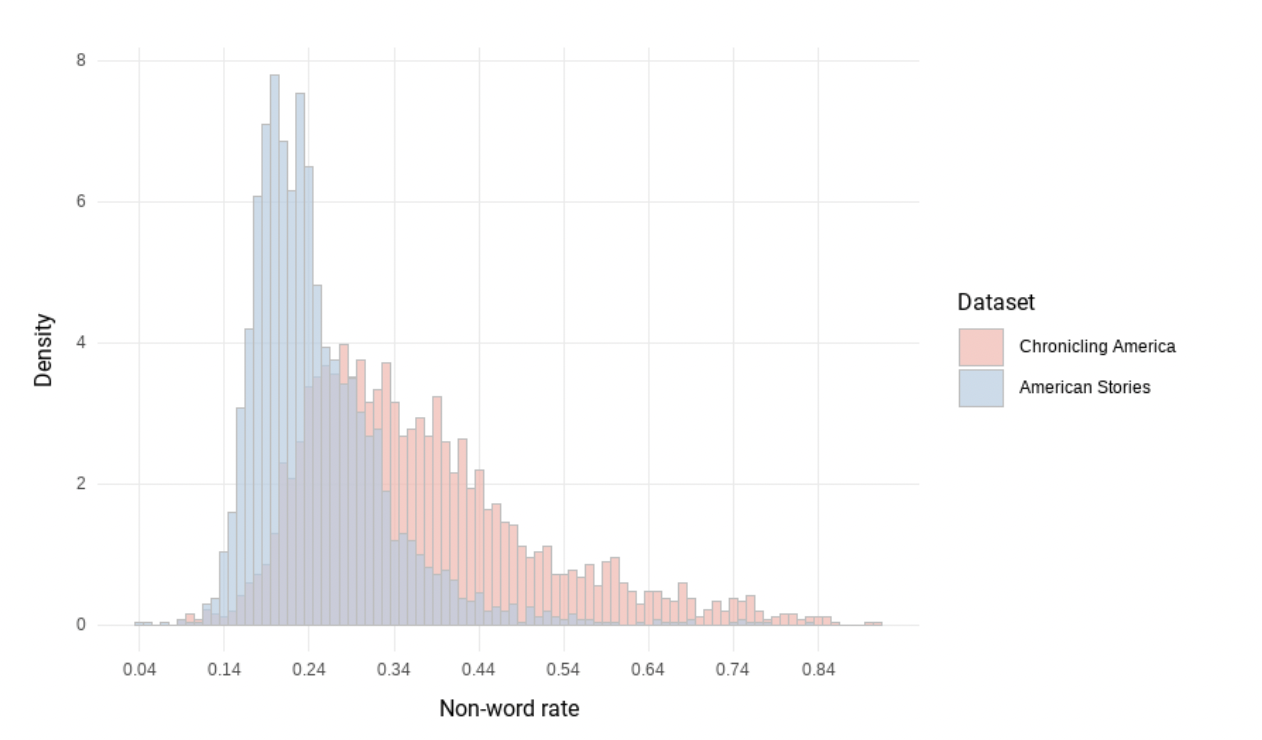
Our texts are high quality. This figure compares the non-word rate in our custom OCR to the Library of Congress OCR. Differences are due to a combination of our high-quality custom-OCR and filtering of illegible content and ads before OCRing.
Interested in a later period? See our massive scale headlines dataset (1920s-80s) and paper, consisting of locally written headlines from news wire articles

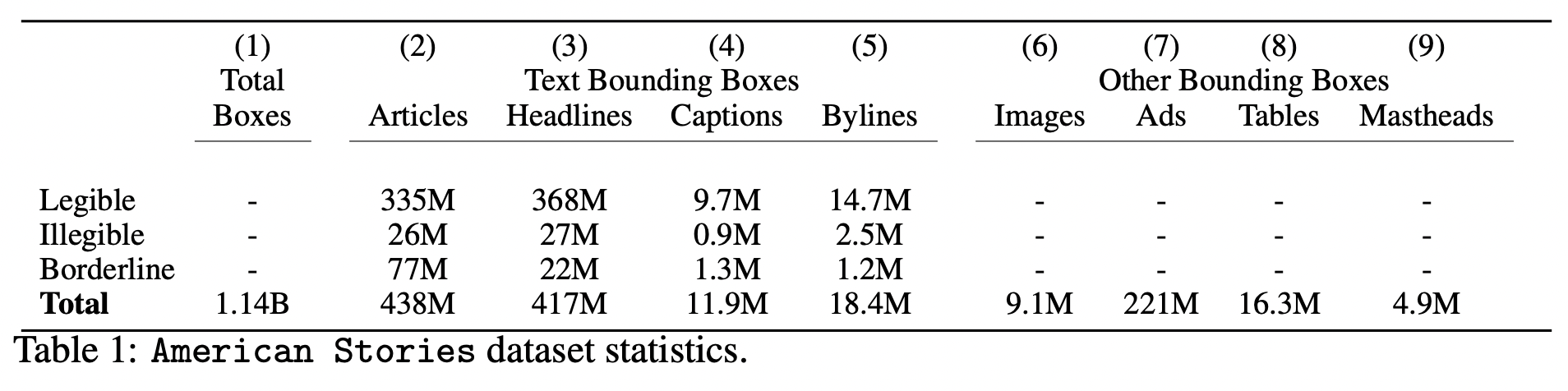
We’re pretty pumped to have a billion+ observations in a historical dataset description table.
If you think American Stories may be useful for you, please like or download. It is challenging to fund dataset/open-source projects, and we need to show that people find our work useful so we can do more!
Funding: Harvard Data Science Initiative, Harvard Catalyst, Harvard Griffin Fund, and MS Azure