Object Detection
Topics
This post covers the fifteenth lecture in the course: “Object Detection and Document Image Analysis.”
This lecture covers object detection models, covering the Fast R-CNN series, YOLO, transformer-based backbones, and document applications. Object detection is fundamental to working with documents, a common source of unstructured data in economics.
Lecture Video
Object Detection

Document Image Analysis
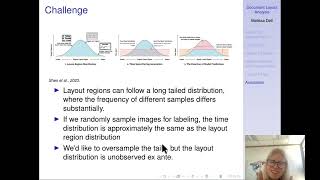
References Cited in Lecture 15: Object Detection and Document Image Analysis
Region CNNs
Girshick, Ross, Jeff Donahue, Trevor Darrell, and Jitendra Malik. “Rich feature hierarchies for accurate object detection and semantic segmentation.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 580-587. 2014. https://doi.org/10.1109/CVPR.2014.81
Girshick, Ross. “Fast R-CNN.” In Proceedings of the IEEE international conference on computer vision, pp. 1440-1448. 2015. https://doi.org/10.1109/ICCV.2015.169.
Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. “Faster R-CNN: Towards real-time object detection with region proposal networks.” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137-1149. 2017. https://doi.org/10.1109/TPAMI.2016.2577031.
He, Kaiming, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. “Mask R-CNN.” In Proceedings of the IEEE international conference on computer vision, pp. 2961-2969. 2017. https://doi.org/10.1109/ICCV.2017.322.
Kirillov, Alexander, Ross Girshick, Kaiming He, and Piotr Dollár. “Panoptic feature pyramid networks.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6399-6408. 2019.
Cai, Z. and Vasconcelos, N., 2019. “Cascade R-CNN: high quality object detection and instance segmentation.” IEEE transactions on pattern analysis and machine intelligence, 43(5), pp.1483-1498.
YOLO
Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. “You only look once: Unified, real-time object detection.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779-788. 2016.
G. Jocher, YOLOv5 by Ultralytics (2020)
Transformer Methods
Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. “End-to-end object detection with transformers.” In European Conference on Computer Vision, pp. 213-229. Springer, Cham, 2020. (DETR)
Liu, Ze, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. “Swin Transformer: Hierarchical vision transformer using shifted windows.” arXiv preprint arXiv:2103.14030 (2021). (Swin)
Semantic Segmentation
Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3431-3440. 2015.
Implementation
Z. Shen, R. Zhang, M. Dell, B. C. G. Lee, J. Carlson, W. Li, Layoutparser: A unified toolkit for deep learning based document image analysis, International Conference on Document Analysis and Recognition 12821 (2021).
Lin, Tsung-Yi, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. “Microsoft coco: Common objects in context.” In European conference on computer vision, pp. 740-755. Springer, Cham, 2014.
Wu, Yuxin, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. “Detectron2.” 2019.
Chen, Kai, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun et al. “MMDetection: Open mmlab detection toolbox and benchmark.” arXiv preprint arXiv:1906.07155 (2019).
Shen, Zejiang, Kaixuan Zhang, and Melissa Dell. “A Large Dataset of Historical Japanese Documents with Complex Layouts.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 548-549. 2020. https://doi.org/10.1109/CVPRW50498.2020.00282.
Tkachenko, Maxim, Mikhail Malyuk, Nikita Shevchenko, Andrey Holmanyuk, and Nikolai Liubimov. “Label studio.” Software. GitHub repository. 2020.
Object discovery
Hénaff, Olivier J., Skanda Koppula, Evan Shelhamer, Daniel Zoran, Andrew Jaegle, Andrew Zisserman, João Carreira, and Relja Arandjelović. “Object discovery and representation networks.” European conference on computer vision, pp.123-143. (2022)
Image Source: www.layout-parser.github.io