Vision and Audio Transformers
Topics
This post covers the sixth lecture in the course: “Vision and Audio Transformers.”
The transformer architecture has made major inroads in vision in recent years, with key advancements covered in this lecture. Similar recent advancements are also covered in the audio space.
Lecture Video
References Cited in Lecture 4: The Transformer and Transformer Language Models
Academic Papers
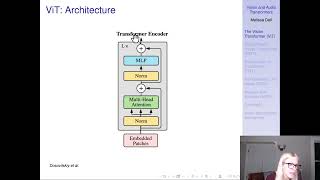
Original Vision Transfomer Paper
- Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020). (Seminal ViT paper)
Further Work with Image Transformers
-
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., & Jégou, H. (2021, July). Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning (pp. 10347-10357). PMLR. (DEIT)
-
Grill, Jean-Bastien, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch et al. “Bootstrap your own latent-a new approach to self-supervised learning.” Advances in neural information processing systems 33 (2020): 21271-21284
-
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9650-9660). (DINO)
-
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000-16009). (MAE)
-
Ali, Alaaeldin, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev et al. “Xcit: Cross-covariance image transformers.” Advances in neural information processing systems 34 (2021): 20014-20027. (XCiT)
-
Bai, Yutong, Jieru Mei, Alan L. Yuille, and Cihang Xie. “Are Transformers more robust than CNNs?.” Advances in Neural Information Processing Systems 34 (2021): 26831-26843.
-
Wang, Zeyu, Yutong Bai, Yuyin Zhou, and Cihang Xie. “Can CNNs Be More Robust Than Transformers?” arXiv preprint arXiv:2206.03452 (2022).
-
Chen, Xinlei, Saining Xie, and Kaiming He. “An empirical study of training self-supervised vision transformers.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9640-9649. 2021.
Other Resources
- Vision Transformers Explained R. Anand. (Ignore the final paragraphs headed “Transformers aren’t mainstream yet”)
- Vision Transformers on paperswithcode
- PyTorch Image Models (timm). Open repository of image models, including XciT, Swin, ViT, etc
- Benchmarking of timm models (Colab Notebook)
- Which Image Models are Best? (Kaggle)
Code Bases
Using timm to implement these models is strongly recommended. Here are a few official implementations:
Image Source: https://www.v7labs.com/blog/vision-transformer-guide